Cracking MD5 hashes by simultaneous usage of Multiple GPUs and CPUs over multiple machines in a network
Date
June, 2013
Conference
UACEE EEC 2013, Dehradun
Paper download rank
Download from UACEE’s seekdl Download Conference Presentation
Authors: Solely authored
Abstract: Cryptographic Hash functions find ubiquitous use in various applications like digital signatures, message authentication codes and other forms of security. Their associated vulnerabilities therefore make them a prevalent target for cyber criminals. General means of defeating hash based authentication involves both discovering and exploiting inherent weakness in cryptographic hash functions or by straight forward brute force attack on the hash Digest. The latter in most cases presents to be an extremely time intensive task. Recent times have however seen usage of GPUs for brute forcing hashes thus significantly accelerating the rate of brute forced hashes. This has further been extended to use simultaneous usage of multiple GPUs over multiple machines. Usage of CPUs for brute forcing have more or less lost importance over the advent of GPU based cracking. This paper presents an efficient method of maximally using computing resources by simultaneously using Graphics Processing Units (GPUs) and Central Processing Units (CPUs) of machines over a network and compares its efficiency against using networked GPUs alone. This also discusses the possibility of currently unseen exploitation of computing power of botnets.
Languages
Tools
This research project aims to provide a framework to crack generic hashes using the combined power of CUDA supporting NVidia Graphics cards and CPUs over a network. This features a single program that be deployed across a network in a decentralized fashion. No single node acts as a server or client in particular. Any single node can be used to feed the required hash that has to cracked along with its particulars like character set, key type and key length.
Highlights:
- Approximately ‘N’ times faster than using a single GPU (N, being the total GPUs used)
- Zero deployment prerequisites/dependencies.
- Automated network awareness. IP address needn’t be supplied. Completely decentralized.
- No single nodes failure can compromise the working of the network as a whole.
- Highly customizable Hash cracking parameters.
Critical technique used:
- CUDA power simultaneously combined with multithreaded CPU power.
- MD5 algorithm optimized for maximum performance within CUDA.
Google Scholar Citations earned:
- Barbieri, D.; Cardellini, V.; Filippone, S., “Exhaustive Key Search on Clusters of GPUs,”Parallel & Distributed Processing Symposium Workshops (IPDPSW), 2014 IEEE International , vol., no., pp.1160,1168, 19-23 May 2014; doi: 10.1109/IPDPSW.2014.131
Accolades:
- Conference paper download count rank: 13th out of 82 papers
- Journal Appearance (UACEE International Journal of Advances in Computer Science and its Applications)
The paper also demonstrates how one can simultaneously use the computing resources of CPUs and GPUs across multiple machines in a network. Till the writing of this paper, a setup with the highest hash cracking rate was a custom machine built with an extended bus supporting 25 GPUs. With the technique mentioned in this paper, a user could achieve the same power without the use of custom hardware and by making use of a modified open source tool.
Objectives:
The objectives were to lay foundation for a system where the nodes in a “cracking” were decentralized and where the was equally distributed among the participating nodes.
Methodology:
All the nodes present in the network first establish contact with each other. A user can use anyone of the nodes to feed in a job (this refers to request to crack a particular MD5 hash). Once a node had accepted the job, all nodes including itself simultaneously attempt at breaking the hash. Any node drop outs are detected by the other nodes by means of a time out mechanism. The other nodes adjust according to the drop in computing nodes. BarsWF is use to brute force the hash cracking on each of the individual machines. The modification of this program involves adding a functionality in which the program stops at a designated end trial key. This is used to implement the mechanism by which the system can correctly manage work load distribution in the network.
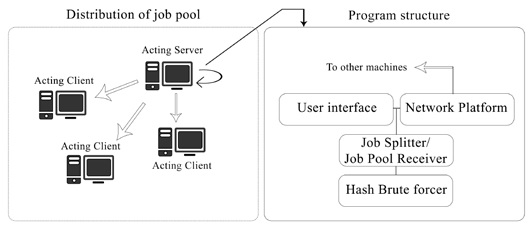
System overview
Limitations:
This method splits the workload distribution in such a way that the number of participating nodes cannot be more than the character count specified in the cracking process.
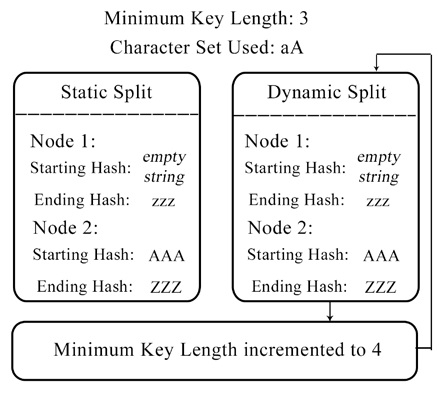
The dynamic workload distribution algorithm
Results:
Overall hash cracking rates across the a test network showed that the workloads were evenly distributed that the combined hash rates grew linear to the contributing nodes. This showed that a user could simply use this technique to possess high hash rates by usage of a network of powerful machines instead of a custom machine which would probably cost more than all the machines would together. This also suggests a possible attack in which botnet herders could come to possess extremely high rates of hash cracking by usage of computing resources in their botnets.
Further work:
The workload distribution limitation in this paper is overcome in my second paper where I present a constant cost function to split down huge amounts of workloads to even millions of participating nodes. Also, I present detailed methods on how a botnet herder could actually implement such a system and I present calculated estimates of hash cracking power obtained if such a system was implemented. I also discuss the potential dangers if such a system is implemented and exploited.
Screenshots:
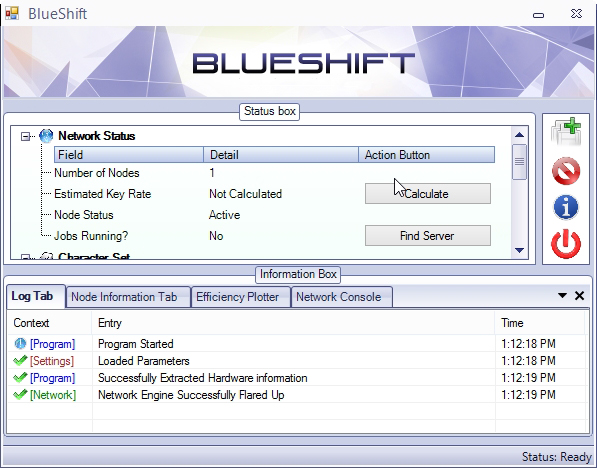
The main screen. This shows all participating nodes and their hardware information. The user can feed jobs from any one of the by using the “Create job” button.
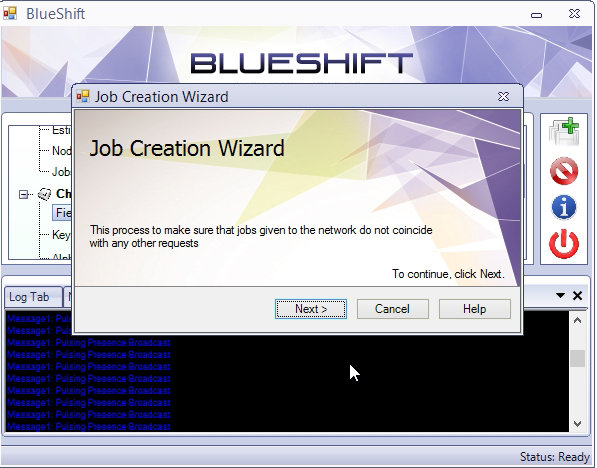
Job creation wizard. Screen – 1
Job creation wizard. Screen – 2.

Job creation wizard. Screen – 3
Job creation wizard. Screen – 4
Settings screen. (Dictionary distribution was left unimplemented)

Job split screen
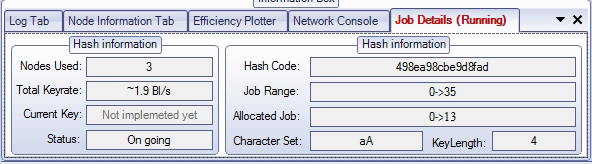
This shows the ongoing job details